Manish Gupta

Principal Consultant at Wipro Limited
Data Scientist | ML | DL | NLP | GenAI
Email: mgupta.power@gmail.com
View My LinkedIn Profile
View My Tableau Profile
View My Kaggle Profile
Read my articles on Medium
INCOME QUALIFICATION
Introduction: I have worked on this project titled “Income Qualification” to fulfil mandatory criteria towards “Machine Learning” module of my PGP in Data Science course from Simplilearn.

Objective: To identify the level of income qualification needed for the families for social welfare program in Latin America.
Many social programs have a hard time ensuring that the right people are given enough aid. It’s tricky when a program focuses on the poorest segment of the population. This segment of the population can’t provide the necessary income and expense records to prove that they qualify.
In Latin America, a popular method called Proxy Means Test (PMT) uses an algorithm to verify income qualification. With PMT, agencies use a model that considers a family’s observable household attributes like the material of their walls and ceiling or the assets found in their homes to classify them and predict their level of need. While this is an improvement, accuracy remains a problem as the region’s population grows and poverty declines.
The Inter-American Development Bank (IDB) believes that new methods beyond traditional econometrics, based on a dataset of Costa Rican household characteristics, might help improve PMT’s performance. I used RandomForestClassifier in Python to create model for predicting income level and used GridSearchCV to improve model performance. I also used Matplotlib and Seaborn to visualize data.

Project Description:
- Understand input dataset since dataset is huge and contains 143 columns and 9557 observations altogether in training data provided.
- Pre-processing of data including missing value treatment in various columns.
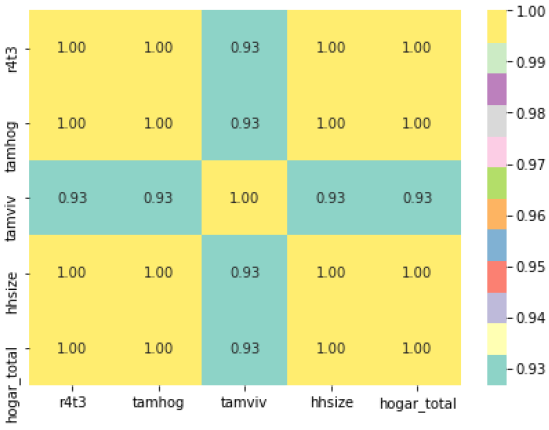
- Checking and dropping one of the highly correlated feature pairs in household and individual features in dataset.
- Convert object type variables into numerical data.
- Creating Machine Learning model with Random Forest Classifier.
- Evaluate performance of model using various metrics such as confusion matrix and classification report.
- Improving model performance using GridSearchCV.
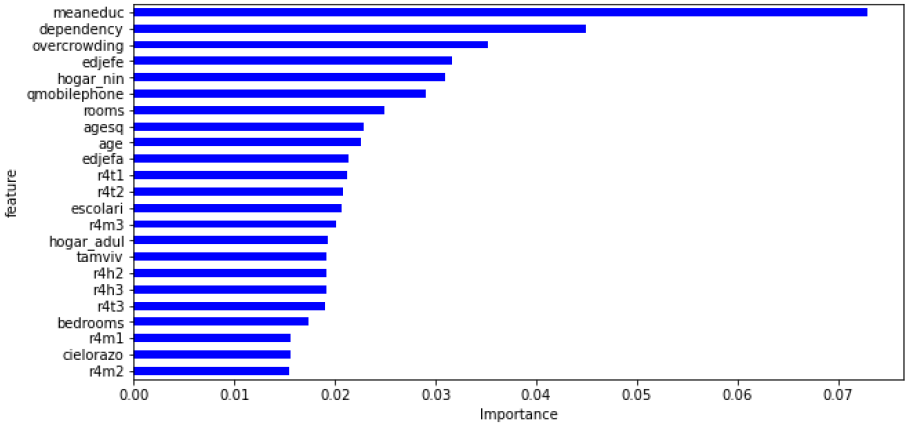
- Finally finding important features among predictor and their importance in model performance.
Tools used: This project was done in Python language and popular libraries like Pandas, Numpy, Matplotlib, Seaborn, RandomForest Classifier, GridSearchCV were used in this project.
Copyright (c) Manish Gupta